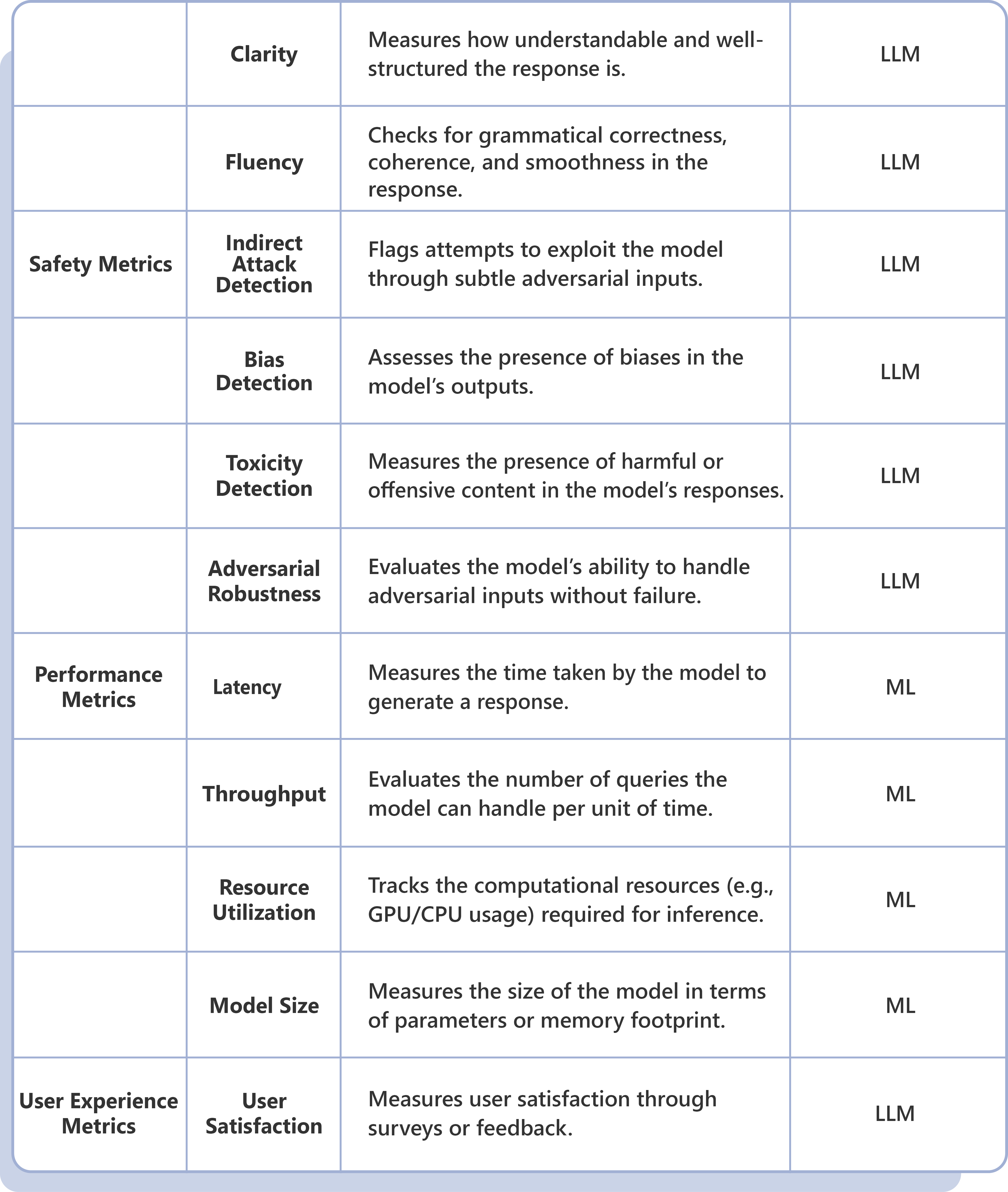
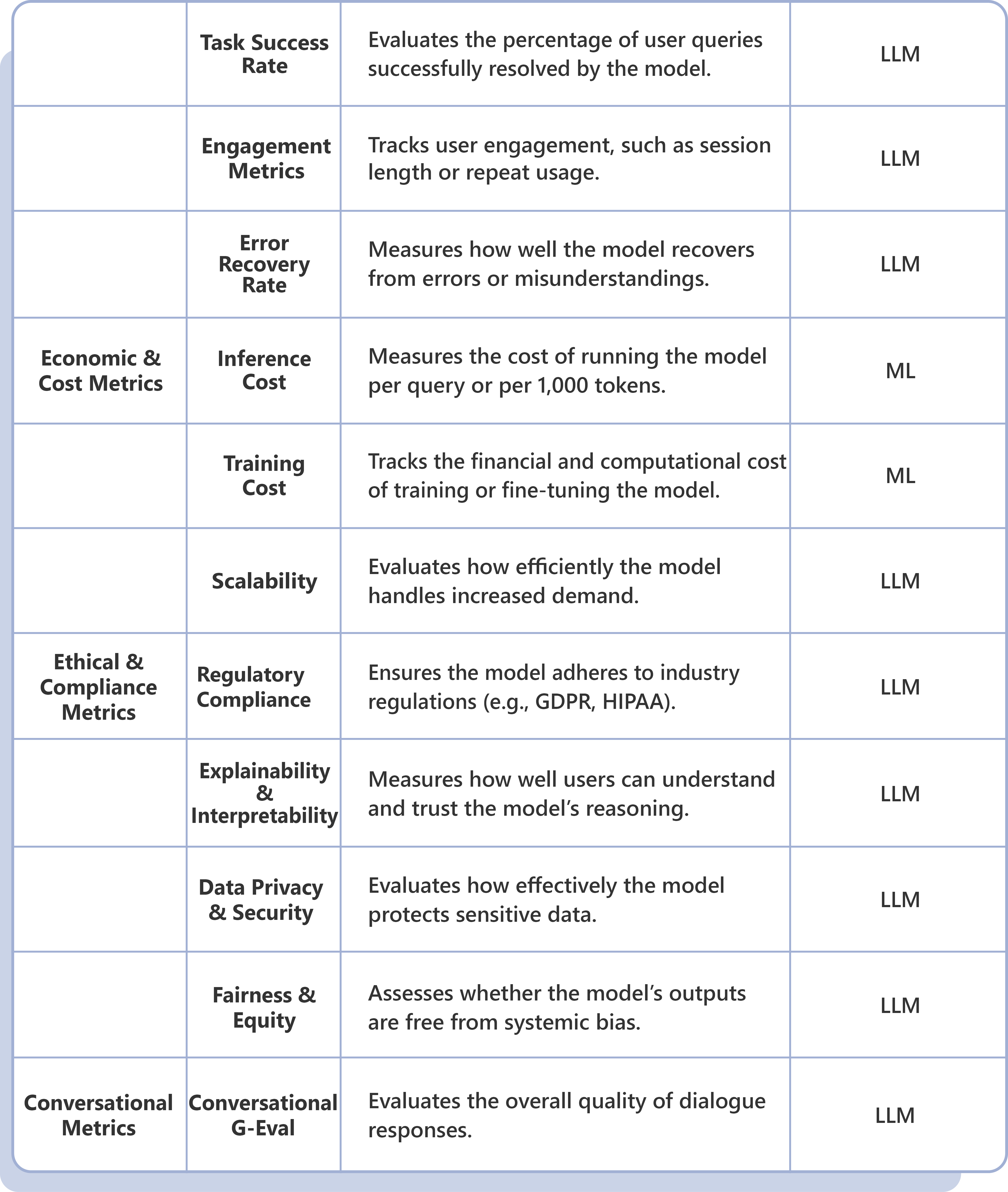
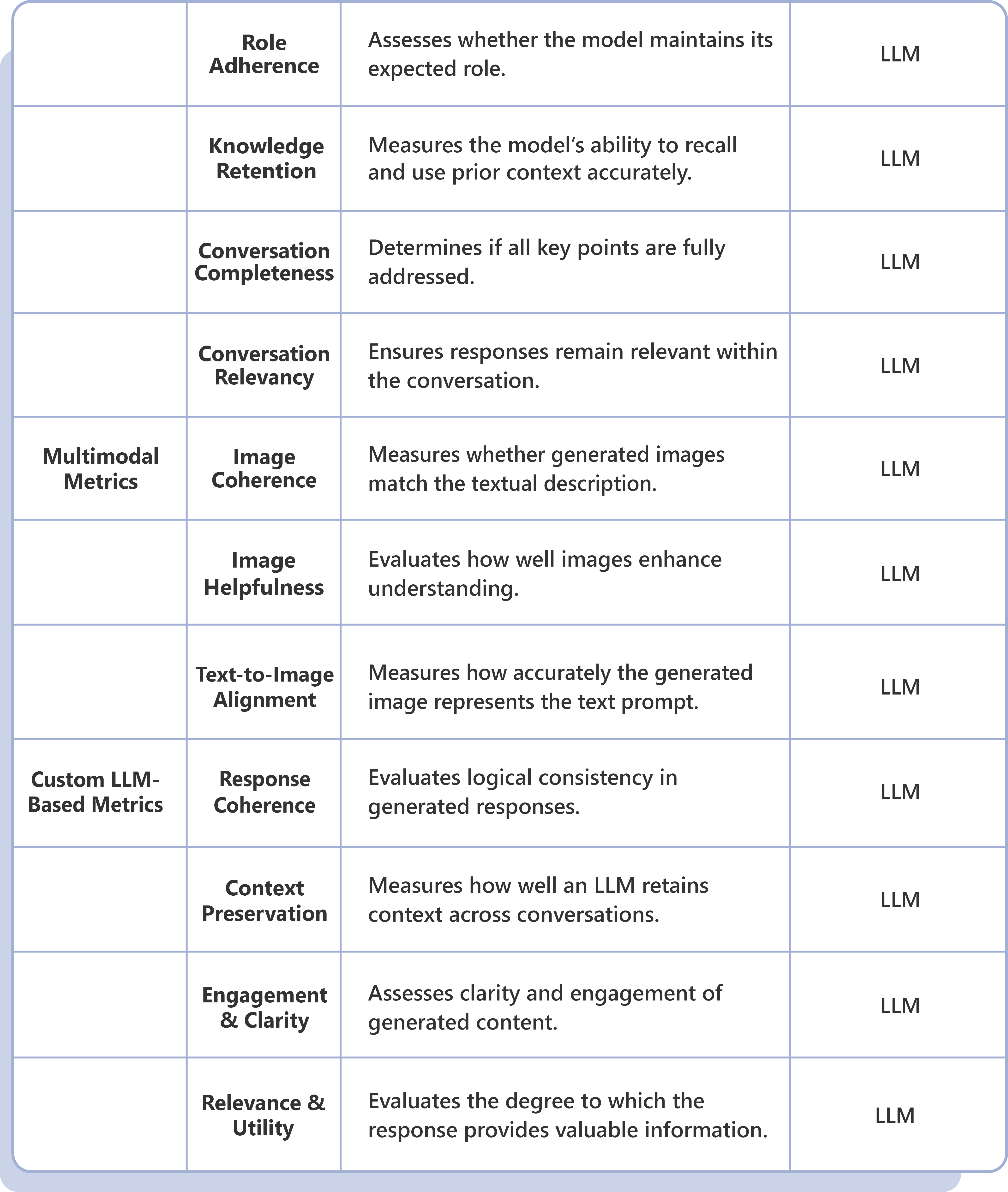
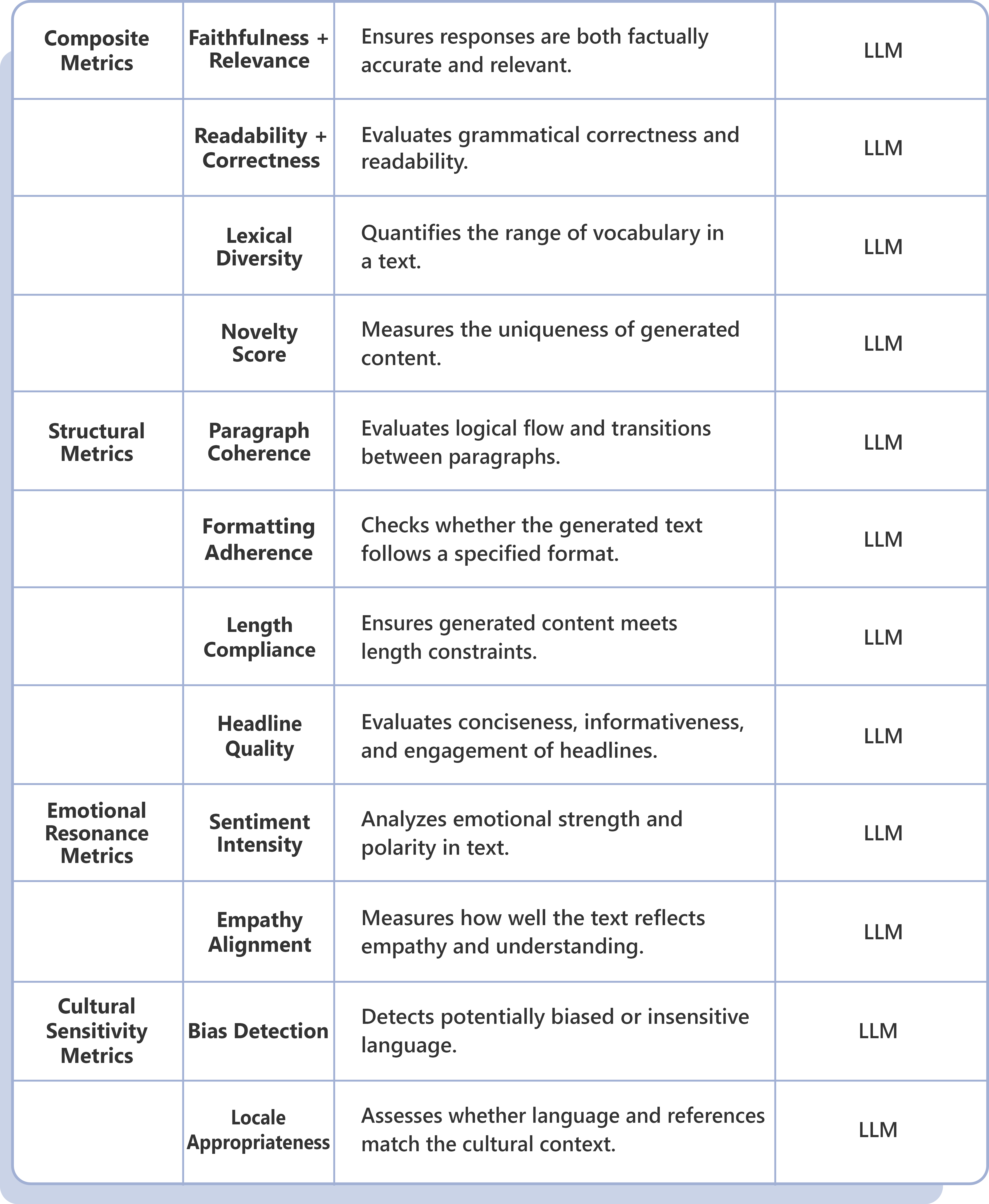
LLM Evaluation Framework: Strategic Drivers & Business Imperatives

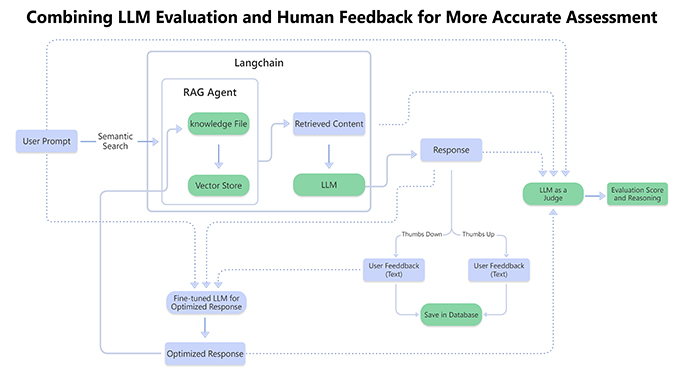
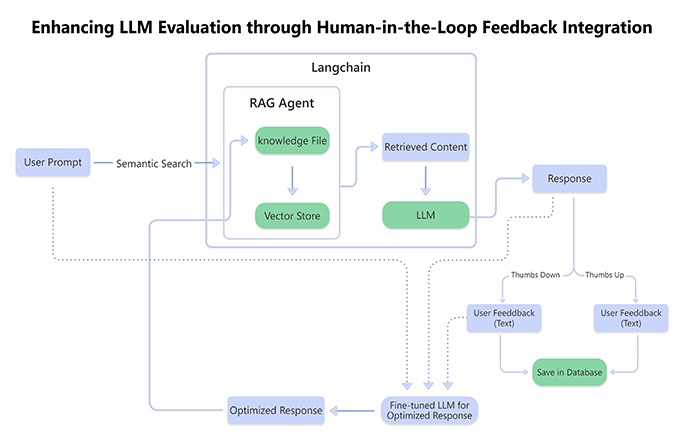
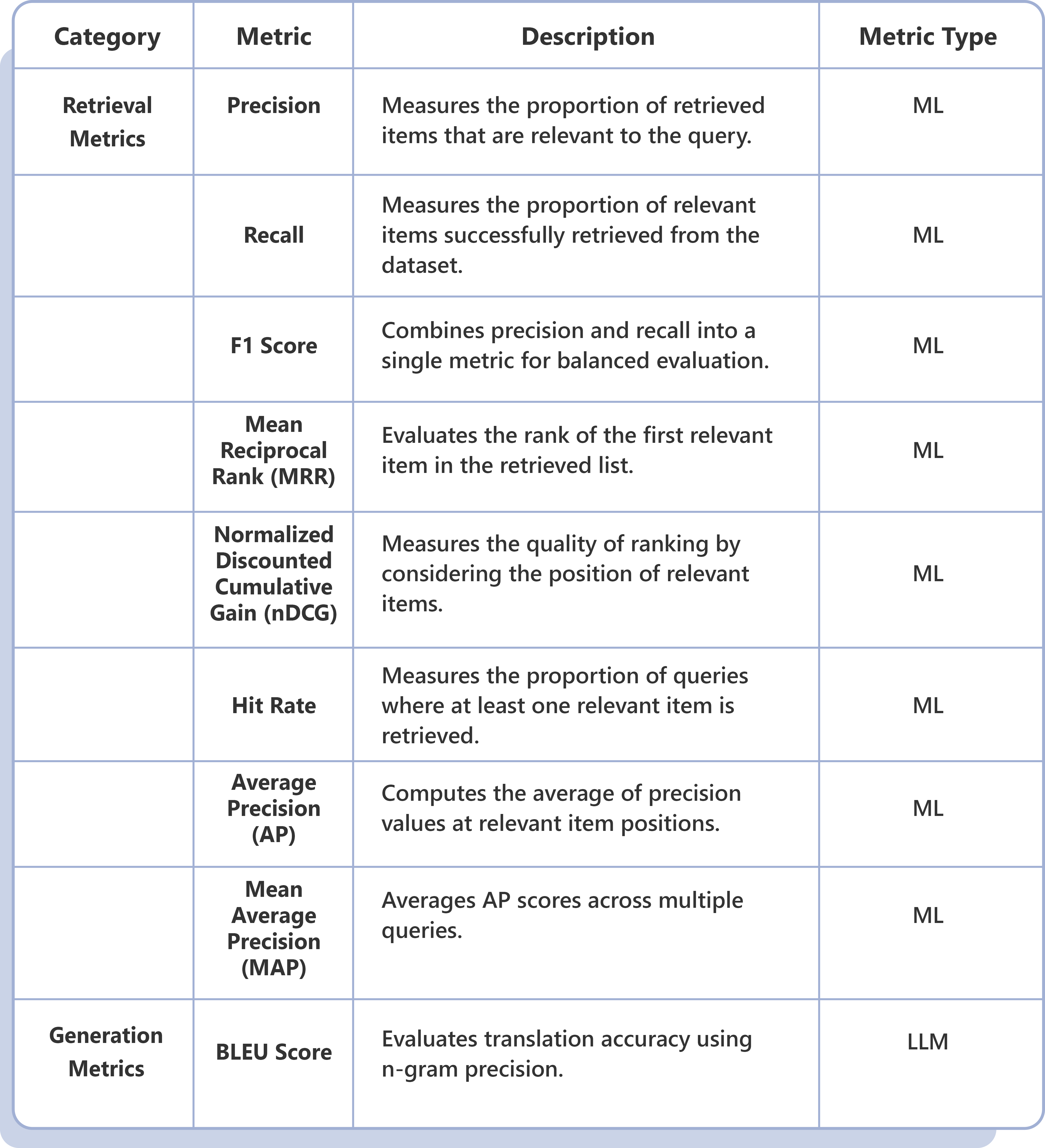
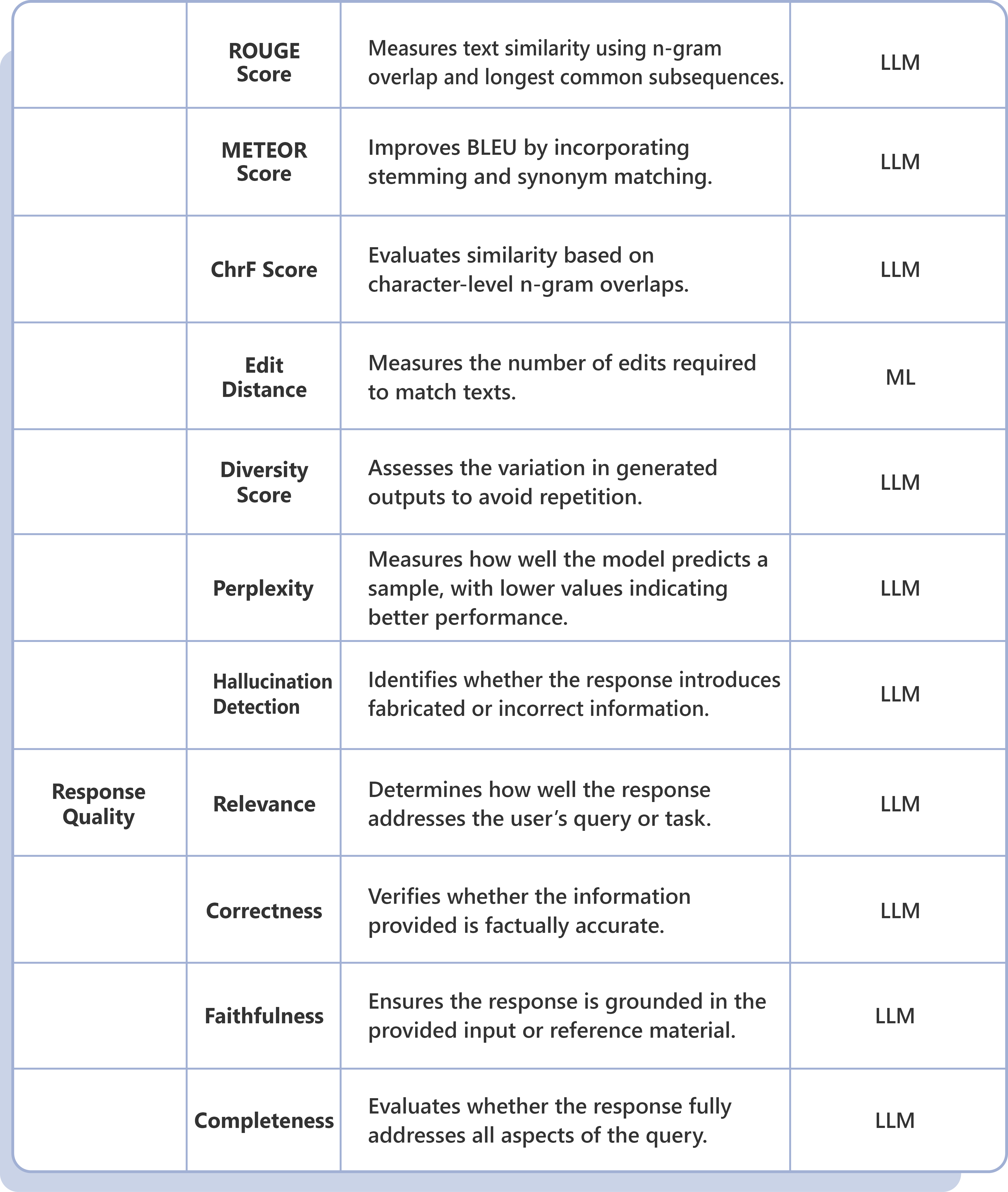
Our comprehensive LLM Evaluation Framework helps organizations navigate the rapidly evolving GenAI landscape by providing structured assessment criteria and methodologies for selecting optimal language models.
- Rapidly Evolving LLM Landscape (New models emerging monthly)
- Model Performance Variations (GPT vs. Claude vs. LLaMA vs. Custom Models)
- Vendor Lock-in Concerns (Azure/OpenAI/Anthropic dependencies)
- Cost Per Token Optimization (Different pricing models across providers)
- LLM Hallucination Management
- Model-Specific Security & Data Privacy Requirements
- Multi-Model Orchestration Needs
- Domain-Specific Model Selection
- Prompt Engineering Efficiency
- AI Governance & Responsible AI Compliance